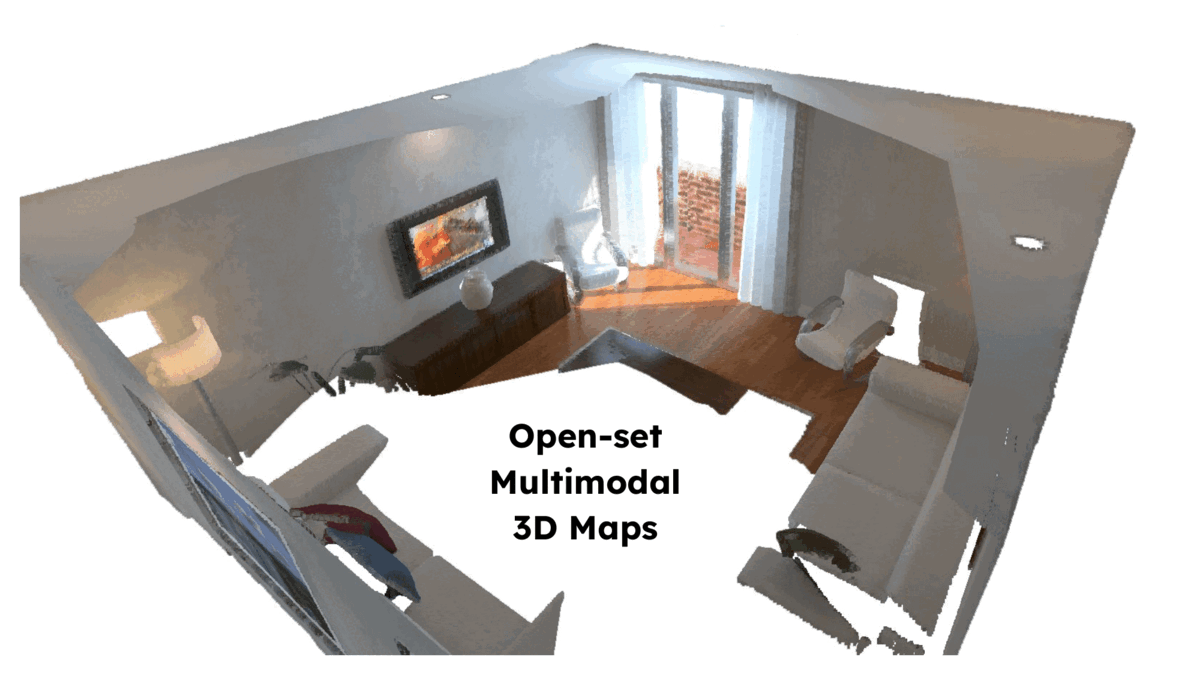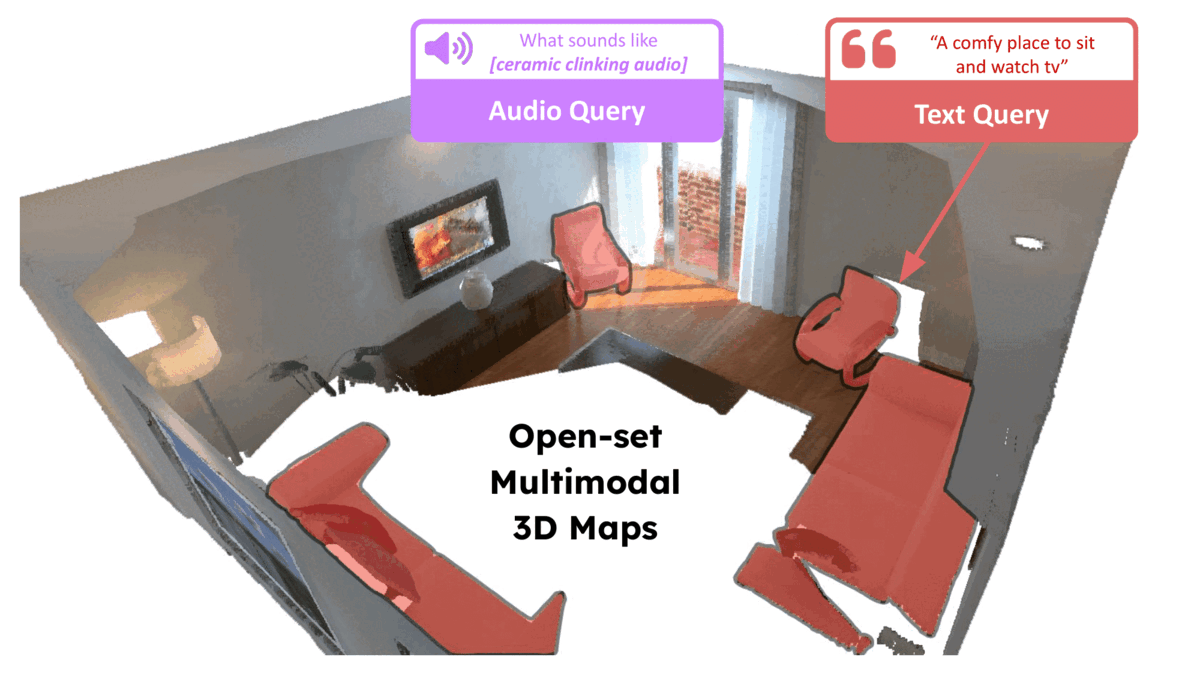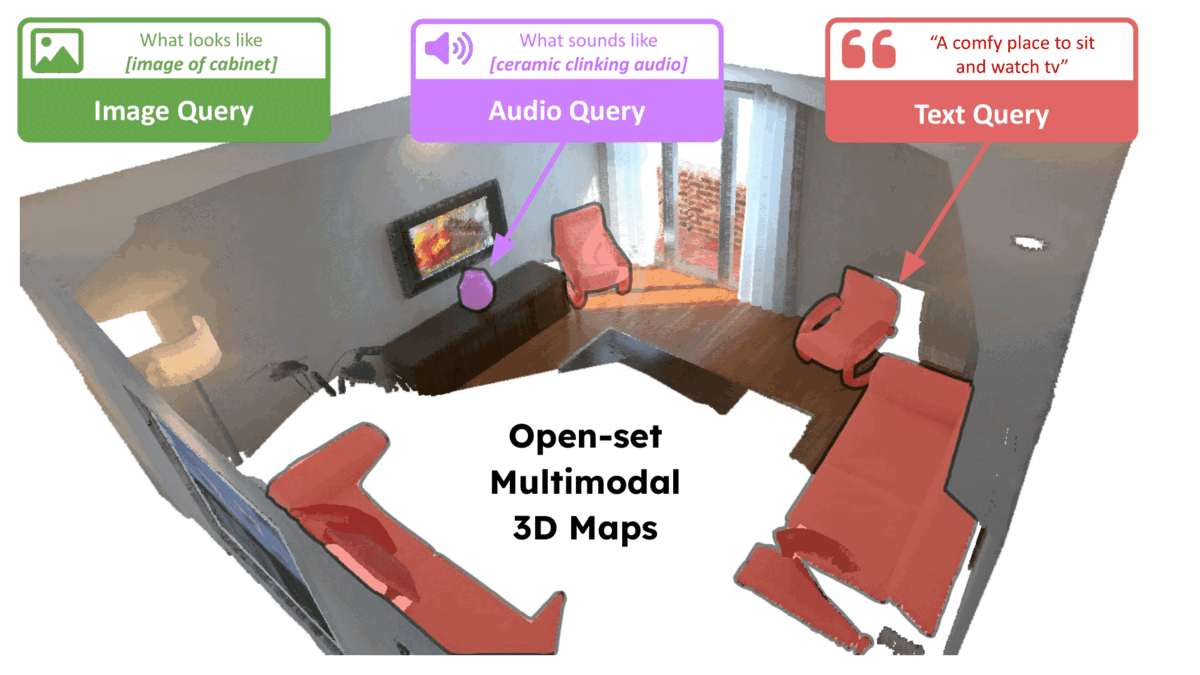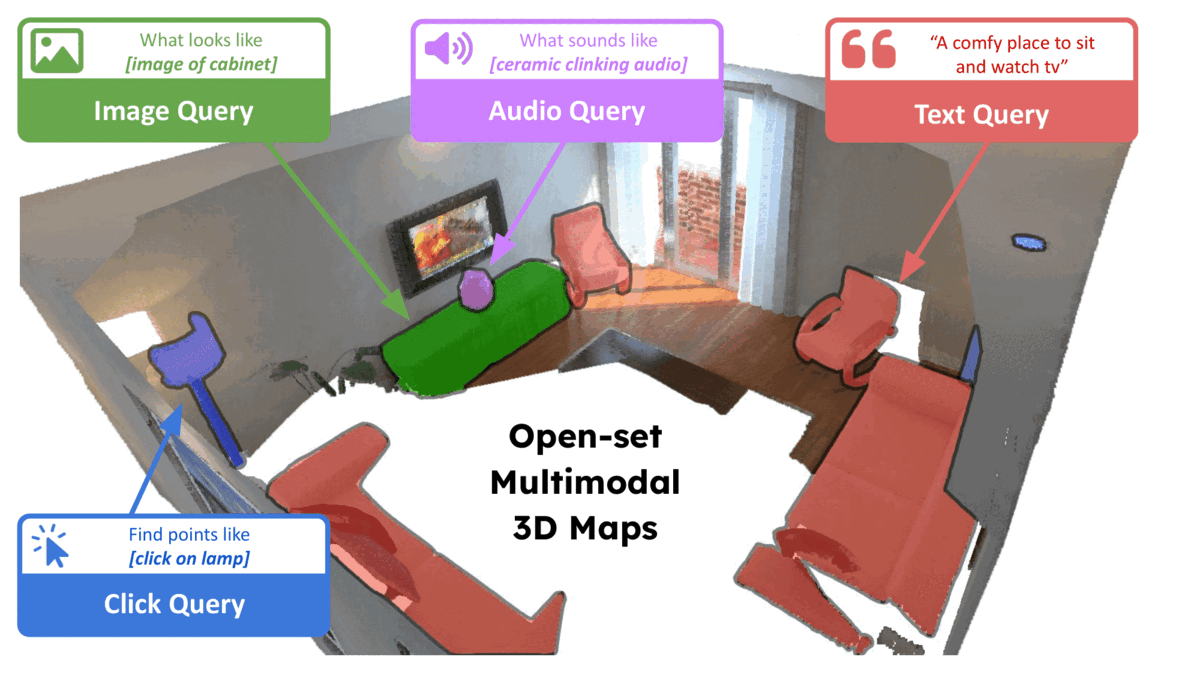
Given the pace of AI research these days, it is extremely challenging to keep up with all of the work around foundation models and open-set perception. We list below a few key approaches that we have come across after beginning work on ConceptFusion. If we may have inadvertently missed out on key concurrent work, please reach out to us over email (or better, open a pull request on our GitHub page).
CLIP-Fields encodes features from language and vision-language models into a compact, scene-specific neural network trained to predict feature embeddings from 3D point coordinates; to enable open-set visual understanding tasks.
OpenScene demonstrates that features from pixel-aligned 2D vision-language models can be distilled to 3D, generalize to new scenes, and perform better than their 2D counterparts.
Deng et al. demonstrate interesting ways of learning hierarchical scene abstractions by distilling features from 2D vision-language foundation models, and smart ways of interpreting captions from 2D captioning approaches.
Feature-realistic neural fusion demonstrates the integration of DINO features into a real-time neural mapping and positioning system.
Semantic Abstraction uses CLIP features to generate 3D features for reasoning over long-tailed categories, for scene completion and detecting occluded objects from language.
Say-Can demonstrates the applicability of large language models as task-planners, and leverage a set of low-level skills to execute these plans in the real world. Also related to this line of work are VL-Maps, NLMap-SayCan, and CoWs, which demonstrate the benefits of having a map queryable via language.
Language embedded radiance fields (LERF) trains a NeRF that additionally encodes CLIP and DINO features for language-based concept retrieval.
3D concept learning from multi-view images (3D-CLR) introduces a dataset for 3D multi-view visual question answering, and proposes a concept learning framework that leverages pixel-aligned language embeddings from LSeg. They additionally train a set of neurosymbolic reasoning modules that loosely inspire our spatial query modules.